In some cases, you might find that data in Netpeak Spider differ from what you see on a website. Here is the list of reasons why it may happen:
-
An invalid server response when accessing a webpage. This issue may be caused due to the fact that the server, on which a website is located, doesn’t work correctly when receiving a large number of requests or there is a protection from a lot simultaneous requests installed on it.
This situation may be indicated by:- A significant increase of a server response time (TTFB);
-
A large number of crawled pages which return the 5xx response code.
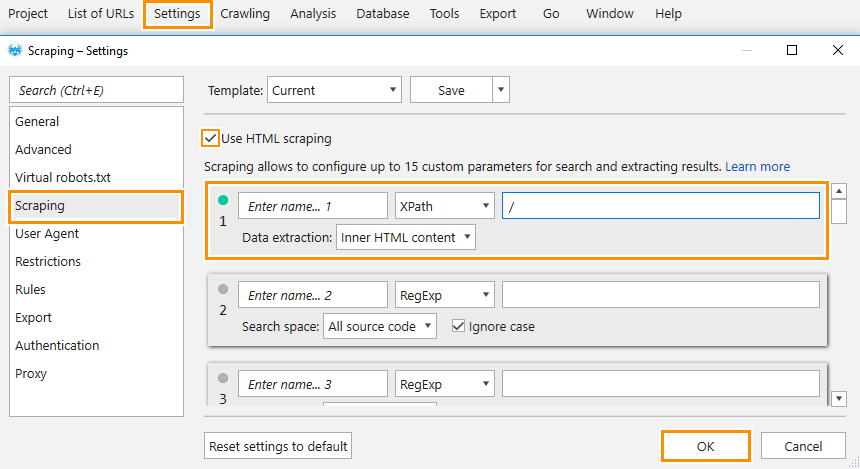
Sometimes, a server may return the ‘200 OK‘ response code, but the page content is not full and/or invalid. It can be found according to missing values in many parameters. The easiest way to check what source code has been returned to the program during the crawling is using ‘XPath‘ for scraping of the whole document. You should set ‘/‘ path, choose the ‘Inner HTML content‘ option and start the crawling.
-
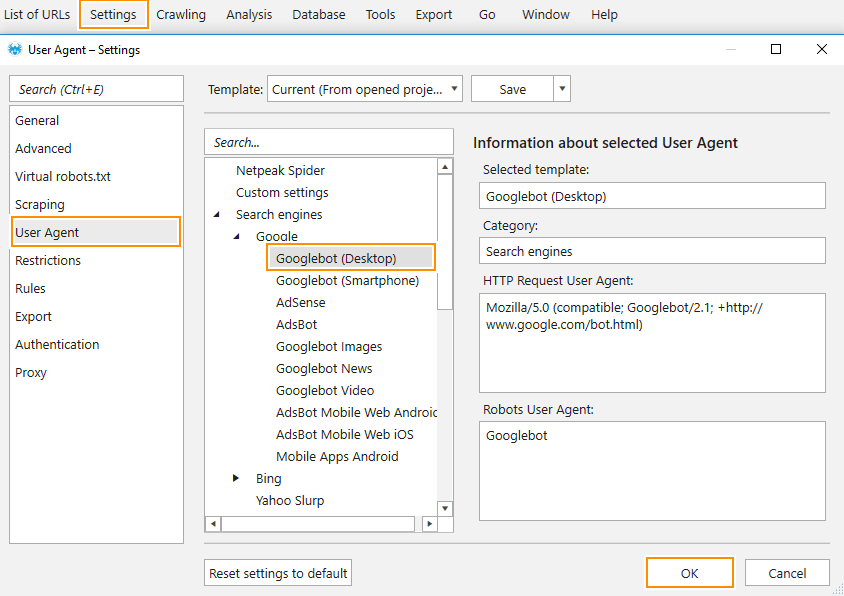
Different content can be shown to different users, devices, and search robots. Thus, you can see two different versions of a website in Netpeak Spider and in a browser because they were created for different User Agents (Netpeak Spider uses Google Chrome by default).
To find out how this parameter affects on retrieved data, you need to change a User Agent on the appropriate tab of the settings. For example: Search Engines → Google → Googlebot;
-
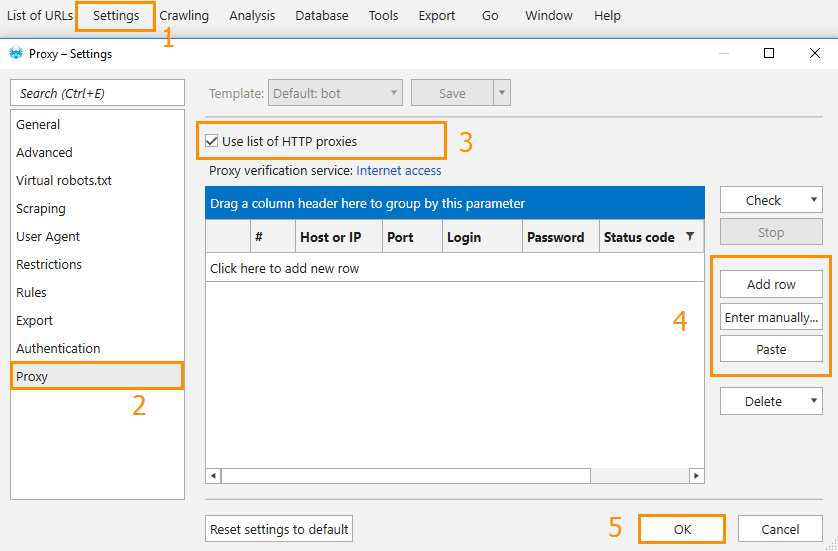
Some websites may show different content (e.g. different language, prices, etc.) depending on device location which was used to send the request. Use access via proxy to view different versions of a website;
-
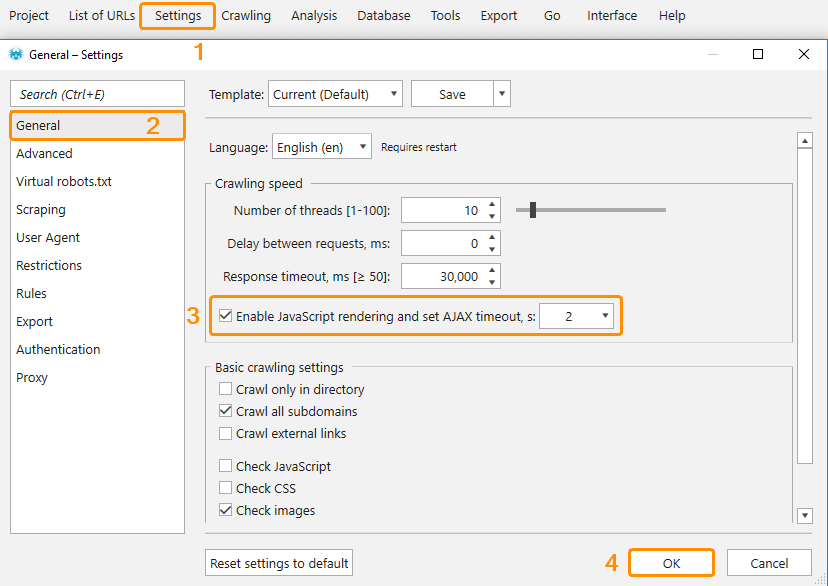
A website may have data which is displayed to a user using JavaScript (JS). By default, Netpeak Spider crawls only static HTML code without JavaScript rendering.
To start crawling with JS rendering, tick the option ‘Enable JavaScript rendering‘ on the ‘General‘ tab of the program settings. If necessary, change the Ajax Timeout (the delay in 2 seconds is set by default).
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article