The built-in feature ‘Virtual robots.txt‘ allows testing new or renewed robots.txt file without changing an existing file in the website root directory.
To configure the virtual robots.txt, go to the ‘Settings‘ → the ‘Virtual robots.txt‘ tab, tick the ‘Use virtual robots.txt‘ checkbox, write your directives and click the ‘OK‘ button to save them.
To start testing set directives, enter the address of a website in the ‘Initial URL‘ field and start crawling using the ‘Start‘ button.
The tool provides the following functions:
- Copy → to copy the content into the clipboard;
- Save (Alt+S) → to export the created robots.txt file into your device as a text document;
- Paste → to paste the text from the clipboard;
- Clear → to delete all content from the window.
The directives from the virtual robots.txt file will affect such parameters as:
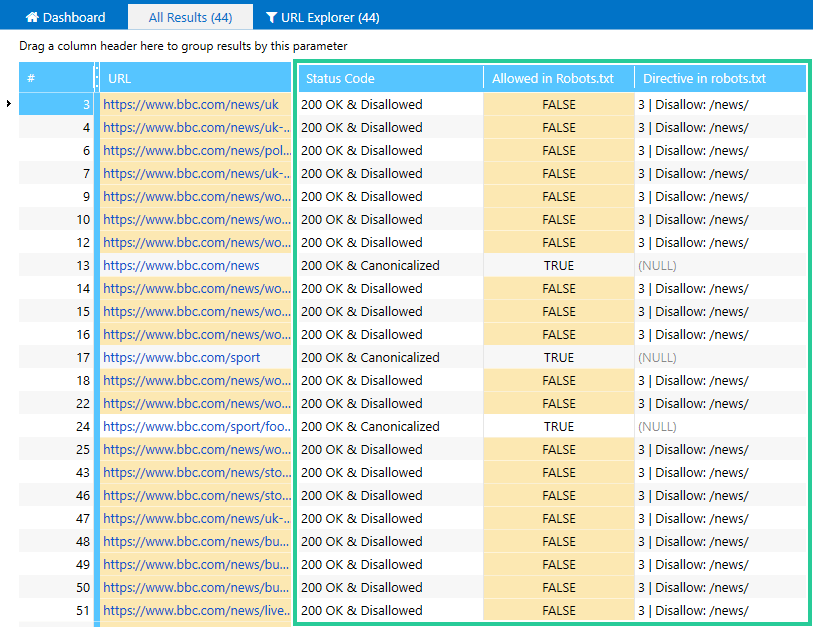
- ‘Status code‘ → if access to a page is disallowed by a directive in the robots.txt, the ‘Disallowed‘ will be added to the status code
- ‘Allowed in robots.txt‘ → the ‘TRUE‘ value is displayed if access to a page is allowed by the ‘Allow‘ directive or the file doesn’t contain any directives, disallowing the indexing of a page. Otherwise, ‘FALSE‘ value is displayed.
- ‘Directive in robots.txt‘ → shows which directive allows or disallows access to a page and its number in the file. The value ‘(NULL)‘ is displayed when there is no instruction for the current URL.
To make the crawler obey the directives written in the robots.txt file, activate robots.txt consideration on the ‘Advanced‘ tab in the program settings.
Note: if the ‘virtual robots.txt‘ feature is disabled, then the program will follow and display the instructions written in the realrobots.txt file. Chosen User Agent may also affect crawling and results.
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article